What Is ChatGPT Doing ... and Why Does It Work?

GET THE #1 EMAIL FOR EXECUTIVES
Subscribe to get the weekly email newsletter loved by 1000+ executives. It's FREE!
Summary of "What Is ChatGPT Doing ... and Why Does It Work?" by Stephen Wolfram
Links
Stephen Wolfram's book "What Is ChatGPT Doing ... and Why Does It Work?" delves into the inner workings of ChatGPT. Wolfram explores the architecture, training, and implications of ChatGPT, providing clear examples and explanations along the way.
The fact that this is freely available on the Wolfram website is amazing. It's 105 pages long and is a perfect read that is a step up from a typical blog post without the overhead that some AI books have that make them quite difficult to read.
We just covered the Wolfram website in a previous post which has a whole bunch of articles on AI, physics, and mathematics.
Key topics that the book covers
-
Introduction to ChatGPT: Explaining the purpose of ChatGPT and it's capabilities.
-
Architecture and Training: The book delves into the architecture of ChatGPT and how it is trained to generate human-like text.
-
Implications of ChatGPT: Wolfram discusses the implications of ChatGPT for AI, language understanding, and human-computer interaction.
-
Future Directions: The book concludes with a discussion of future directions for ChatGPT and AI in general.
We don't know why this works!
That quote led me down a bit of a rabbit hole, but it's true. We don't know why ChatGPT works. It's a bit like the universe. We don't know why it works, but we know it does.
I found this interesting quote by Sam Bowman
So there’s two connected big concerning unknowns. The first is that we don’t really know what they’re doing in any deep sense. If we open up ChatGPT or a system like it and look inside, you just see millions of numbers flipping around a few hundred times a second, and we just have no idea what any of it means. With only the tiniest of exceptions, we can’t look inside these things and say, “Oh, here’s what concepts it’s using, here’s what kind of rules of reasoning it’s using. Here’s what it does and doesn’t know in any deep way.” We just don’t understand what’s going on here. We built it, we trained it, but we don’t know what it’s doing.
*Reference: Sam Bowman Interview
Anyway, that isn't the main takeaway of the book! We are here to understand what ChatGPT is doing and why it works.
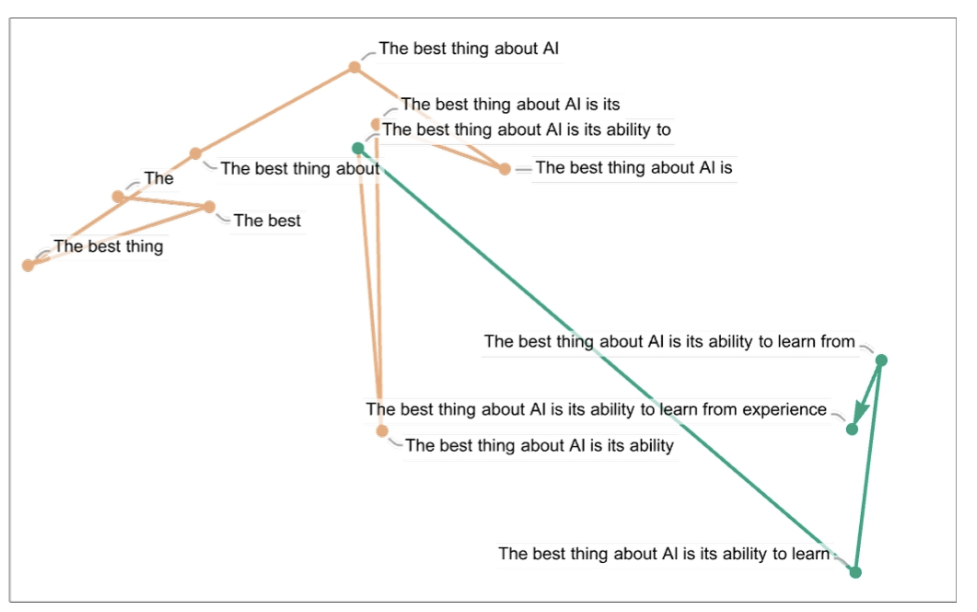
One word at a time
I enjoyed this initial description of how ChatGPT works:

Simple, right? He used an example showing that if you just sample how often the different letters occur in English text, and then just pick letters at random according to these frequencies, you get something that looks a bit like English text.

The temperature of words
Your intuition would be that you always just take the highest probability next word, but it turns out if you do that, you get a very flat and boring essay that starts to repeat itself. The concept of temperature is introduced to make the essay more interesting. Temperature essentially means that you sometimes pick lower-ranked words to make the essay more interesting.
It turns out that a 0.8 temperature seems to be the best for essay generation. You will also see this parameter in AI models when you use them.
Here is an example with 3 different temperature settings for email.
Example 1 - Low Temperature (0.2 - 0.5)
Professional follow-up on the status of an invoice
Dear [Client Name],
I hope this email finds you well.
I am writing to follow up on the status of Invoice #12345, which was issued on [Date]. As of today, we have not yet received payment for this invoice. We kindly request that you review this matter and let us know if there are any issues or if additional information is needed to process the payment.
If the payment has already been made, please disregard this message. Otherwise, we would appreciate your prompt attention to this matter.
Thank you for your cooperation.
Best regards,
Example 2 - Moderate Temperature (0.6 - 0.7)
Friendly yet professional follow-up on the status of an invoice
Hi [Client Name],
I hope you're doing well!
I'm reaching out to check on the status of Invoice #12345, which we sent over on [Date]. We haven't seen the payment come through yet and just wanted to make sure everything is in order on your end. If there's any issue or if you need additional information from us, please let me know.
If the payment is already in process, thank you, and please ignore this email. Otherwise, we would appreciate your assistance in settling this invoice at your earliest convenience.
Thanks so much for your attention to this. Looking forward to hearing from you soon.
Best,
Example 3 - High Temperature (0.8 - 1.0)
Casual follow-up on the status of an invoice
Hey [Client Name],
Hope all's well on your end!
Just wanted to touch base regarding Invoice #12345 that we sent on [Date]. Haven't seen the payment come through yet and wanted to make sure everything is good to go on your side. If there's any issue or if you need more info, just let me know.
If the payment is already on its way, awesome, and you can ignore this email. Otherwise, we'd appreciate it if you could take a look when you get a chance.
Thanks a bunch and talk soon!
ChatGPT is awesome at estimating probabilities of words
So the model essentially repeats the same process as the letter example but with words. It estimates the probabilities of words based on a large corpus of text and generates sentences by picking words at random according to these probabilities. This is the essence of ChatGPT's ability to generate human-like text.
The big idea is to make a model that lets us estimate the probabilities with which sequences should occur—even though we’ve never explicitly seen those sequences in the corpus of text we’ve looked at. And at the core of ChatGPT is precisely a so-called “large language model” (LLM) that’s been built to do a good job of estimating those probabilities.
Neural Networks
How is this done? Through a neural network. The neural network is trained on a large corpus of text to estimate the probabilities of sequences of words. This is the essence of ChatGPT's ability to generate human-like text. The book goes into a lot of detail on how this is achieved.
A visualisation of ChatGPT words in their embedding space
The learning and training of ChatGPT
The Fundamental Tension of Learnability and Computational Irreducibility
I liked this concept talking about how there is a tension between learnability and computational irreducibility. Learning involves compressing data by leveraging regularities, but computational irreducibility implies that there’s a limit to what regularities there may be.
An example of this
An example of this is weather forecasting. While meteorologists use patterns and historical data to predict weather, the atmosphere's behavior is ultimately computationally irreducible. Despite advancements in technology and data analysis, long-term weather predictions remain challenging due to the atmosphere's chaotic nature.
The fundamental tension between learnability and computational irreducibility lies in the contrast between the ease of extracting patterns from data and the inherent complexity of certain processes. Learning, at its core, seeks to simplify and generalise data by identifying and leveraging regularities, making it possible to predict and understand phenomena with reduced effort. However, computational irreducibility asserts that some systems or processes are so complex that they cannot be simplified or predicted without fully simulating each step.
Other examples where this tension plays out
Financial Markets: Traders and analysts use historical data and patterns to predict stock prices and market trends. However, the market is influenced by countless variables and human behaviors, making it computationally irreducible. Sudden events or shifts in sentiment can render predictions inaccurate, demonstrating the limits of learnability in financial forecasting.
Biological Systems: Scientists study genetic sequences and biological pathways to understand diseases and develop treatments. While certain regularities and patterns can be identified, the sheer complexity of biological interactions and the influence of countless factors make precise predictions challenging. This complexity showcases the tension between the desire to learn and simplify versus the irreducibility of biological processes.
Urban Planning: Urban planners use models and historical data to design efficient cities and predict future growth. However, the myriad of human behaviors, economic factors, and environmental changes make urban development highly unpredictable. This unpredictability highlights the computational irreducibility of urban systems, despite efforts to learn and model them effectively.
Have computers become vastly more powerful?
Well its interesting because he argues that the tasks that ChatGPT is doing are not fundamentally different from what computers were able to do before. The difference is that now we have models like ChatGPT that can do these tasks more efficiently and effectively.
Quotes around tokens and words
How ChatGPT works
The book explains how ChatGPT operates in three basic stages:
-
Token Sequence to Embedding: ChatGPT takes the sequence of tokens corresponding to the text and finds an embedding that represents these tokens.
-
Neural Network Operation: The embedding is processed through a neural network, with values rippling through successive layers to produce a new embedding.
-
Token Probability Generation: The last part of the new embedding generates an array of about 50,000 values that represent probabilities for different possible next tokens.
The computational cost of generating text
I found it interesting just how much computation is required to generate text!
"But for each token that’s produced, there still have to be 175 billion calculations done (and in the end a bit more)—so that, yes, it’s not surprising that it can take a while to generate a long piece of text with ChatGPT."
The simplicity of language
The future of ChatGPT & laws of thought
I really enjoyed the conclusion of the book where he talks about the future of ChatGPT and the implications of its success. Essentially there might be other laws of thought out there that we can discover.
What laws of thought might we discover?
Well for that, I did the main thing that we should do in an article like this... I asked ChatGPT!
Prompt: What are three example of potential laws of thought that could be out there?
Law of Conceptual Association: This potential law might explain how different concepts are linked together in human cognition. For instance, it could outline the principles by which the brain connects ideas like "apple" and "fruit" or "vehicle" and "car." Understanding this law could enhance our ability to design AI systems that mimic human thought processes more closely, allowing them to draw connections between seemingly disparate ideas with greater accuracy and relevance.
Law of Cognitive Economy: This law could describe how the human brain prioritizes information processing to optimize mental efficiency. It might detail how we allocate cognitive resources to tasks based on their perceived importance or relevance, and how we filter out unnecessary information. Discovering and formalizing this law could lead to AI systems that manage resources and prioritize tasks in a manner similar to human thinking, improving their ability to handle complex, multitasking environments.
Law of Semantic Generalization: This law could define how humans generalize from specific experiences to broader concepts. For example, it might explain how learning about a specific dog leads to understanding the general concept of "dogs." By making this process explicit, we could develop AI that learns and generalizes from data more effectively, allowing it to apply knowledge gained from specific instances to a wider range of situations, thereby improving its adaptability and problem-solving capabilities.




















